저작자 : 고구마 장수
요즘 간만에 Software tuning의 세계에 빠져봅니다. 뭐 회사일로 바쁜 거지만 그 덕에 뭔가 배울 수 있는 것들이 늘어서 좋습니다. Dual Core CPU가 요즘 화제지요? CPU의 내부 core가 쌍으로 있기 때문에 한개의 칩으로 두개의 CPU를 가지고 있으니 얼마나 편하겠어요. 하지만 사람들이 착각하고 있는 것이 있습니다. CPU가 두개라고 처리속도가 두배가 되지 않는 다는 사실입니다. 이게 무슨 소리냐고요? 자 한번 생각해봅시다. 아래와 같은 for loop가 있다고 해봅시다.
for(int i=0; i<10000; i++) { func(i); }
code 1. Sequential code. 이 프로그램이 수행되는 것은 일반적으로 θ(n)의 복잡도를 지닙니다. 이런 프로그램을 Compiler는 '순차적'으로 수행하게 됩니다. 한데 두개의 CPU가 있을 때는 어떻게 될까요? OS가 나눠서 다 알아서 해줄까요? 그렇게 해주는 OS... 없습니다!!! 만약 Dual CPU나 Dual-Core CPU에서 이렇게 짠 프로그램을 돌려보세요. Single CPU빠른거 하나 끼우는게 더 이익이 됩니다. 그럼 어떻게 해야 될까요? 바로 Parallelization을 해야 합니다. 위의 코드는 이렇게 하면 되겠군요. #pragma omp parallel for for(int i=0; i<10000; i++) { func(i); }
code 2. Parallelized code by OpenMP. 헉!! 이게 뭡니까? 이상한 Precompiler header가 붙어 있지요? 이것은 OpenMP라는 Multi Parallelization을 지원하기 위한 표준기능입니다. 이렇게 하면 저 for문을 몇개의 Thread로 나눠서 병렬처리를 해줍니다. 물론 저렇게만 다 쓰면 되는 것도 아니겠지요? Compiler가 이 OpenMP를 지원해야 되겠지요. 이것은 Intel C++ Compiler나 Visual Studio 2005/2008에서 지원하고 있습니다. 지금은 대부분의 Compiler들이 OpenMP를 지원해 주는 덕에 많이 편해졌습니다. 실제 얼마나 향상이 될까요? 제가 Test해본바로는 Single core CPU에서는 OpenMP를 이용하더라도 전혀 속도의 효과를 보지 못했습니다. 하지만 Dual-core혹은 Dual CPU를 이용하면 두배 이상 빠른 것을 확인했습니다. 이와 같이 CPU core의 숫자와 Parallelization code와는 수학적인 관계가 있습니다. 이것이 바로 Amdhal's law이고 다음과 같이 써집니다. M = 1/ { F + (1-F)*N } M= 속도 증가 배율 F= 선형적인 모듈의 비율 ( 0:1) N= CPU갯수.
이 수식에 따르면 CPU의 갯수가 아무리 많아도 Parallelization이 된 코드가 적으면 아무 소용이 없음을 보여주고 있습니다. 이점 꼭꼭 잊지 마시기 바랍니다. 동시에 Parallelization을 한 다음에는 동작의 무결성을 검사해야 합니다. 이를 위해 Intel에서 제공하는 ThreadChecker나 ThreadProfiler를 이용할 것을 권합니다. 이것들을 쓰려면 당연히 VTune같은 Tool도 있어야 합니다. 평가판이 있으니 시도해 보시기 바랍니다. (Data race, Dead-Lock등의 문제를 잘 찾아줍니다.) 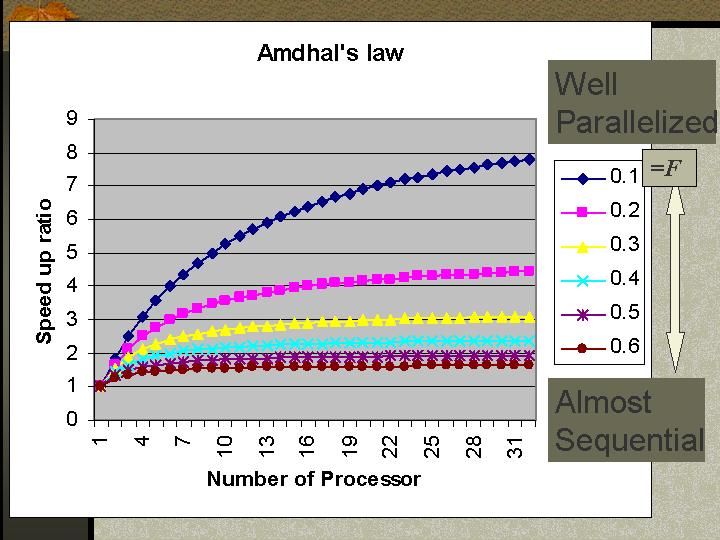 2008년 현재에는 매우 많은 Software들이 병렬처리 기법을 통해 최적화 되어 나왔습니다. ComputerVisionLibrary인 OpenCV만 하더라도 이번에 나온 1.1의 경우에는 OpenMP를 지원하는 버전으로 빌드되어 나와서성능향상에 도움이 되고 있습니다.
2008년 현재에는 매우 많은 Software들이 병렬처리 기법을 통해 최적화 되어 나왔습니다. ComputerVisionLibrary인 OpenCV만 하더라도 이번에 나온 1.1의 경우에는 OpenMP를 지원하는 버전으로 빌드되어 나와서성능향상에 도움이 되고 있습니다.일반적으로 저는 다음 순서대로 최적화 하는 것을 권장하고 있습니다.
- 먼저 Loop의 수를 줄이는 방법을 고민 합니다. ( 100% <= 성능 향상에 기여하는 정도 )
:Loop의 수는 register를 준비하고 처리하는데많은 부하가 걸립니다. 이것을 줄이는 것이 제일 첫 걸음입니다. 이중loop가 돌면 한개로 줄일 수 없는지, 두개의 loop가위/아래로 돌고 있다면 한번 돌 때 처리가 가능한지 뒤져봅니다.이차원 배열을 일차원 배열로 바꿔서 할 경우가 이런 경우일것입니다. - 안해도 될 일 하고 있지 않나요? ( 100% )
:혹시 처리하지 않아도 되는 처리를 한다든가 대충해도 될 처리를 너무 자세하게 처리한다든지 하는 경우를 잡아 주십시오. - Code단순화를 생각해 보세요. ( 80% )
: Greate Code 같은 책들을 보면 C code가 Assembly로 번역되는 것을 생각해 보면서 짜라는 이야기가 나옵니다. 의외로 이것을 생각해 보면 쉽게코드가 단순해집니다. - Data dependency를 줄일 수 있는지 봅니다. ( 40% )
이런 경우 병렬 처리가 매우 힘듭니다.for ( i = 1 ; i < 100; ++i)
a[i] = a[i-1]+ a[i+1]
이것은 시간상에 서로 dependency가 있기 때문입니다. 일반적으로 이런 경우가 제일 없애기 힘듭니다. - 종전에 내가 작성한 코드보다 잘 작성된 코드가 있는가? ( 10% )
: 실제 IPP같은 라이브러리를 보면 직접 image processing코드를 작성하는 것보다 더 잘 되어 있는 경우가 많습니다. 둘중 어떤 것을 쓸지 잘 생각해 보세요. - 병렬처리에 쉽게 코드를 바꾸세요 ( 30% )
:1,3에 사용하는 방법을 이외에 병렬로 처리 되기 쉽게 코드를 바꿔보세요. 10000번할 일을 5000번 씩 나눠 한다든가 처리해야 할 data를 stack에 담아 두었다가 한꺼번에 처리하는 방법도 좋습니다. - 그리고 Loop unrolling을 하세요. ( 10%)
: loop unrolling은 속도를 빠르게 해주지는 않지만 초기 시동 속도를 빠르게 해줍니다. - Tool을 바꿔보세요 ( 20% )
: Visual Studio 2008도 OpenMP를 처리할 때 무한 Thread생성을 하는 경우가 있더군요.Intelcompiler에서는 다행히 그런 일이 없었습니다. 그리고 Intel compiler로 compile하면 현재 출시되는CPU에따라 최적의 Instruction set ( SSE, SSE2등)을 이용할 수 있습니다. 그리고 제발... VTune으로 Hotspot을 먼저 찾고 분석하고 들어가세요. 이것 없이는 아무일도 안하는게 좋습니다. - Intrinsic call을 이용하는 것을 고려해 보세요. ( 30% )
: 이미 대부분의 Compiler들에서는 intrinsic call같은 것들을 이용하게 해줍니다. Intinsic call은각CPU마다 SSE같은 고급 명령 set들에 대해 직접 assembly로 짜지 않고 C함수나 C++class형식으로interface를 만들어 놓은 것입니다. (쓰기 좋습니다. )
성능 향상에 대한 노력은 정말 끝이 없습니다. 기법도 많고 수도 다양합니다. 하지만 가장 중요한 것, "쓰레기를 집어넣으면 쓰레기가 나온다"라는 것입니다. 느린 연산을 하고 있다면 분명 단순화 시키지 않고서는 어떤 기법도 소용없습니다. Compiler를 바꾸거나 라이브러리를 쓰는 것은 그 다음입니다.
댓글 없음:
댓글 쓰기